
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | |||||
| 3 | 4 | 5 | 6 | 7 | 8 | 9 |
| 10 | 11 | 12 | 13 | 14 | 15 | 16 |
| 17 | 18 | 19 | 20 | 21 | 22 | 23 |
| 24 | 25 | 26 | 27 | 28 | 29 | 30 |
- 프로그래머스
- 파이썬
- 배달로봇
- 자율주행
- persistance context
- 포인트클라우드
- 운영체제
- 영속성컨텍스트
- Hibernate
- 논문리뷰
- Python
- JPA
- Java
- 네트워크
- Database
- 이펙티브자바
- 디자인패턴
- Spring Batch
- 자료구조
- 아두이노
- 장애물인식
- 알고리즘
- cartograhper
- 자바ORM표준JPA프로그래밍
- Jetson
- MySQL
- 딥러닝
- 자바
- DeepLearning
- 논문
- Today
- Total
제리 devlog
[JPA] Hibernate 디버깅 (조회 과정) 본문
이번에는 조회 과정을 디버깅해보자.
조회는 2가지 케이스로 나뉜다.
1. 영속성 컨텍스트에 존재하지 않아 db조회가 필요한 경우
2. 영속성 컨텍스트에 값이 존재해 1차 캐시를 반환하는 경우 (db 조회가 필요하지 않은 경우)
조회 과정
@Test
@Transactional
fun `find order`() {
orderJpaRepository.findById(1L)
}
먼저 find가 발생하면 DefaultLoadEventListener에 onLoad메서드가 호출된다.

이 메서드는 doOnLoad를 호출한다. 우선 doOnLoad는 session으로부터 EntityKey를 load 하는데, EntityKey는 entity의 id로 구성된 영속성 컨텍스트에서 엔티티를 구분해주는 key이다.

그리고 이어서 doLoad메서드를 호출한다. 이 메서드에서는 entityKey를 통해 현재 영속성 컨텍스트에 있는 엔티티를 호출한다.
즉, db에 select쿼리를 날리기전에 영속성 컨텍스트에 엔티티가 있는지 확인 작업을 한다. 만약 엔티티가 존재한다면 엔티티를 반환한다.
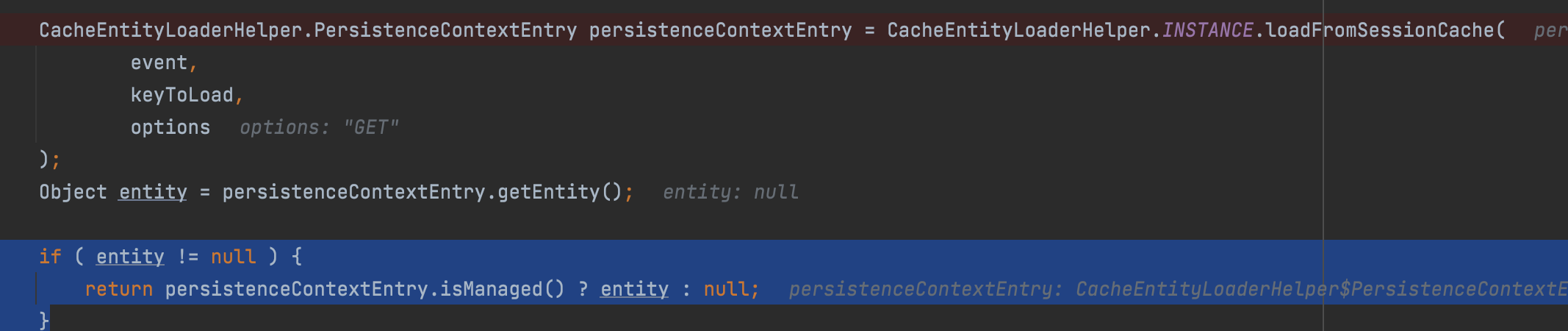
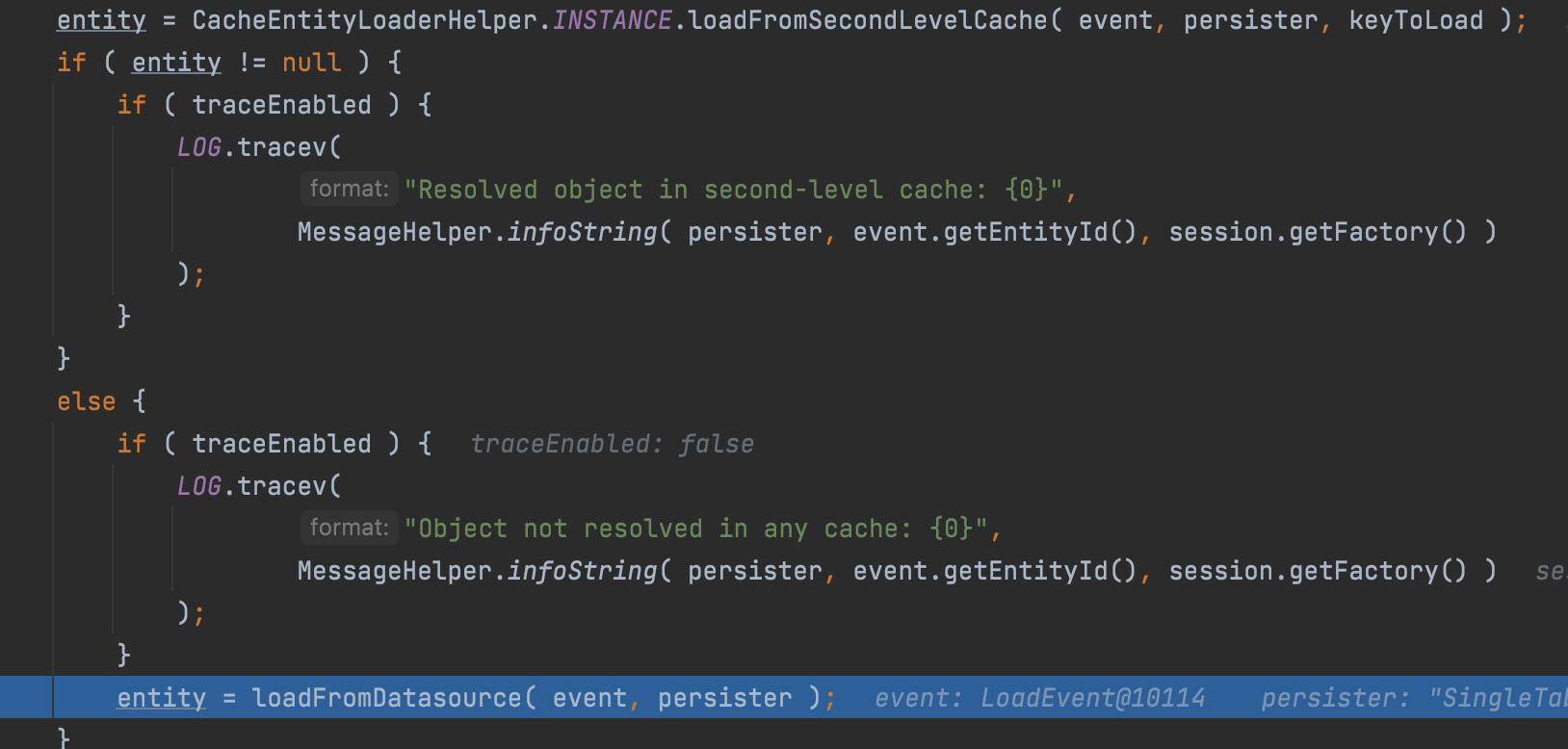
엔티티가 현재 세션에 존재하지 않는다면 다음으로 2차 캐시(애플리케이션 레벨의 캐시)를 조회한다.
2차 캐시가 존재하지 않는다면 db에서 데이터를 가져온다. 이때 영속성 컨텍스트의 entitiesByKey에 엔티티가 등록된다.
정리
하이버네이트의 저장은 다음과 같은 순서로 엔티티가 조회된다.
1. find가 발생하면 DefaultLoadEventListener에 등록된 onLoad가 호출된다.
2. session으로 부터 EntityKey를 load 한다.
3. entityKey를 사용해서 현재 세션에 엔티티가 있는지(영속성 컨텍스트에 존재하는지) 확인한다.
4. 없다면 2차 캐시를 조회한다.
5. 2차 캐시가 없다면 db에서 select쿼리가 발생한다. 이때 영속성 컨텍스트에 엔티티가 저장된다.
'JPA' 카테고리의 다른 글
| [JPA] Hibernate 디버깅 (수정 과정) (0) | 2022.04.24 |
|---|---|
| [JPA] Hibernate 디버깅 (저장 과정) (1) | 2022.04.24 |
| kotlin by 키워드를 사용한 JPA + QueryDsl 통합 Repository 구현 (1) | 2022.03.04 |
| [JPA] 연관 관계를 가진 엔티티 저장 방식 개선 (불필요한 select문 제거) (7) | 2021.05.30 |
| [JPA] 일대일, 다다다 매핑 (0) | 2020.12.02 |



