
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 |
- 자율주행
- persistance context
- cartograhper
- 운영체제
- 논문리뷰
- DeepLearning
- Java
- Jetson
- 이펙티브자바
- JPA
- Database
- Spring Batch
- 아두이노
- 논문
- 자바
- 장애물인식
- 네트워크
- 영속성컨텍스트
- 알고리즘
- 디자인패턴
- 파이썬
- 딥러닝
- Hibernate
- 배달로봇
- 포인트클라우드
- 자바ORM표준JPA프로그래밍
- Python
- 자료구조
- 프로그래머스
- MySQL
- Today
- Total
제리 devlog
Spring Batch 어떤 병렬 처리 방식을 선택해야할까? 본문
들어가며
배치를 돌리다 보면 실행 시간이 오래 걸리는 상황이 발생합니다. 배치의 처리 속도가 중요하지 않다면 문제가 되지 않지만 다른 배치와 dependency가 있어 주어진 시간 내에 완료가 되어야 하는 상황도 빈번하게 발생합니다. 이에 대한 해결책으로 배치의 처리 속도를 향상하는 병렬 처리를 적용해 볼 수 있습니다. Spring Batch에서 데이터를 병렬 처리하는 방법은 다양하기 때문에 상황에 맞게 적절한 병렬 처리 기술을 선택하는 것은 중요합니다. 이번 포스팅에서는 단일 프로세스에서 성능 개선을 위한 chunk 병렬 처리 기술에 대한 특징을 알아보겠습니다.
Chunk에 관한 Background
본격적으로 들어가기 앞서 spring batch에서는 데이터를 어떻게 처리하는지 알고 있어야 합니다.
대부분 배치를 작성할 때는 chunk oriented 한 구조의 배치를 사용합니다.
chunk oriented 한 구조는 데이터를 읽고, 가공하고, 쓰는 과정이 하나의 트랜잭션으로 이뤄지고 이 과정을 반복함으로써 데이터를 처리합니다.

데이터를 한 번에 얼마만큼 처리할지는 chunk size를 조절하여 결정할 수 있습니다.
chunk를 처리하는 과정은 다음과 같습니다.
- read 작업은 chunk size만큼 반복해서 읽고 process로 넘깁니다.
- process는 넘어온 데이터를 반복해서 처리하고 writer로 넘깁니다.
- writer에서는 반복해서 처리하지 않고 processor에서 넘어온 데이터를 한번에 받아서 처리합니다
ex) chunk size=2로 설정된 경우 read(), read() → process(), process() → writer 순으로 실행됩니다.
Spring batch에서 제공하는 병렬 처리의 장점
배치를 병렬 처리할 때 반드시 spring batch에서 제공하는 기능을 사용해야 하는 것을 아닙니다. 배치 로직에서 병렬 처리를 코드로 구현해 줄 수 있습니다. 그럼에도 직접 코드상으로 병렬 처리를 하게 되면 코드의 복잡성은 물론 Spring Batch에서 제공하는 다른 기능을 적절히 사용하기 어려워질 수 있습니다.
예를 들어 아래의 process로직을 코드상으로 병렬 처리하는 상황을 확인해 보겠습니다.
fun process(item: RawData): ProcessedData {
return processData(item)
}
병렬처리를 위해 입출력을 Collection으로 변경하고 CompletableFuture를 사용한 코드입니다.
fun process(item: List<RawData>): List<ProcessedData> {
return item
.map { CompletableFuture.supplyAsync { processData(it) } }
.map { it.join() }
}
이제 변경된 코드의 문제점을 하나씩 살펴보겠습니다.
문제점1 - 예외 처리를 위한 코드 복잡성
Spring Batch에서 chunk처리의 실패를 핸들링하는 방식으로 Skip, Retry 같은 기능을 제공합니다.
이러한 기능은 Step을 생성하는 과정에서 특정 예외클래스를 지정하여 적용합니다.
하지만 위의 코드는 지정한 예외를 잡지 못할 가능성이 높습니다.
CompletableFuture를 사용하면 스레드 내부에서 발생한 예외는 CompletionException으로 Wrapping 되기 때문에 예외를 명시적으로 찾아 반환해 주어야만 지정한 Skip, Retry Exception을 핸들링할 수 있습니다.
이런 이유로 배치 로직은 스레드 내부에서 발생한 예외를 반환하는 로직이 추가되어야 합니다.
fun process(item: List<RawData>): List<ProcessedData> {
return item
.map {
try {
CompletableFuture.supplyAsync { processData(it) }
} catch (e: CompletionException) {
throw e.cause ?: throw e
}
}
.map { it.join() }
}
처음 process로직이랑 비교하면 입출력 포맷 변경, CompletableFuture, 에러 핸들링 로직이 추가되면서 다소 복잡해진 모습입니다.
문제점2 - Skip적용 시 Collection 단위 처리로 인한 정상 데이터 누락
병렬 처리를 위해 데이터 처리 단위를 Collection으로 변경했습니다.
만약, process로 넘어온 100건의 데이터 중 1건의 데이터에서 Skip이 발생했다면 어떻게 될까요?
정상적으로 반영 가능한 99건을 포함하여 100건이 모두 skip 됩니다.
Spring Batch Skip기능 대신 코드에서 직접 Skip로직을 구현할 수도 있지만 코드의 복잡도는 계속 증가합니다.
문제점3 - 트랜잭션 관리
스프링에서 관리하는 트랜잭션은 트랜잭션 리소스를 스레드에 바인딩합니다.
그리고 트랜잭션 내부에서 새로운 스레드가 파생되면 새로운 스레드에는 트랜잭션 리소스가 바인딩되지 않습니다.
즉, 새로운 스레드는 기존의 트랜잭션과 분리됩니다.
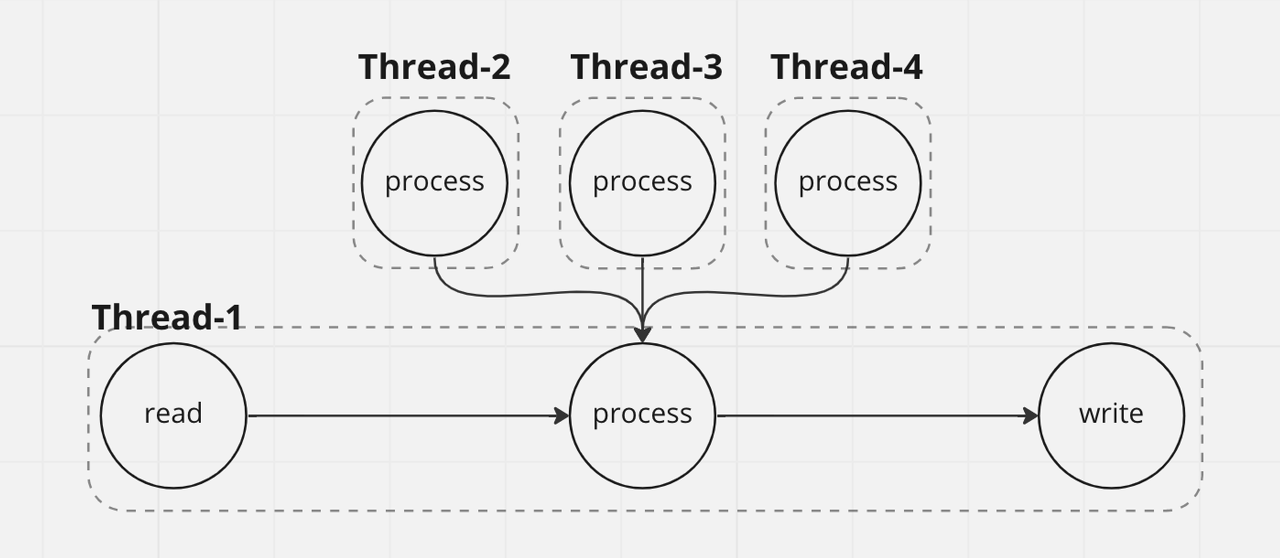
Spring Batch에서는 Thread-1 내부에서 실행되는 Chunk 처리를 트랜잭션으로 처리합니다.
process 처리 중 파생된 Thread-2, 3, 4는 기존의 트랜잭션 범위에서 벗어나게됩니다.
Thread-2, 3, 4에서 새로운 트랜잭션이 열린다면 다음과 같은 문제가 발생합니다.
- write오류로 Thread-1 트랜잭션이 롤백될 때 Thread-2, 3, 4는 롤백되지 않음
- Thread-2,3,4에서 읽은 Jpa Entity를 write에서 lazy loading 하려고 할 때 트랜잭션 종료로 예외 발생
- 비슷하게 파생된 Thread-2,3,4의 영속성 컨텍스트를 writer에서 사용할 수 없습니다.
Spring Batch에서 제공하는 병렬 처리 기능을 사용하면 이런 문제가 해결되나요?
Spring Batch를 사용하면 입출력, 배치 로직을 변경하지 않고 일부 설정을 변경하여 병렬 처리를 할 수 있습니다. 또한, 특정 병렬 처리 방식을 사용하면 트랜잭션에 대한 관리도 용이해집니다.
하지만 프레임워크에서 지원하는 병렬 처리 방식의 한계점도 존재합니다.
프레임 워크상에서 지원하는 병렬 처리의 동작 과정은 한정되어 있습니다. 따라서 실제 원하는 병렬 처리 동작을 지원하지 않을 수 있습니다.
ex) ItemWriter로 넘어오는 items를 내부적으로 병렬처리하는 기능은 프레임 워크에서 지원하지 않습니다.
fun write(items: MutableList<out ProcessedData>) {
...
}
그럼에도 spring batch에서 지원하는 병렬 처리 방식을 숙지하고 있다면 많은 상황에서 프레임워크를 활용하여 복잡한 코드 작성 없이 병렬 처리 기능을 구현할 수 있습니다.
Spring Batch Chunk 병렬 처리 방식
이제 각 병렬 처리 방식의 특징에 대해서 알아보겠습니다.
Multi-threaded Step
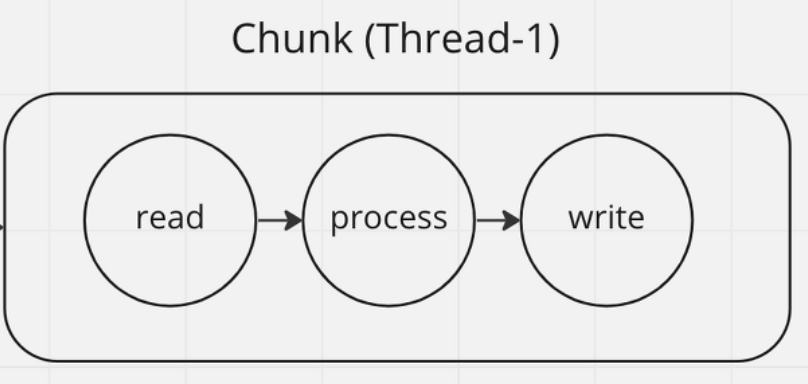
Multi-threaded Step은 아래 그림과 같이 동작합니다.
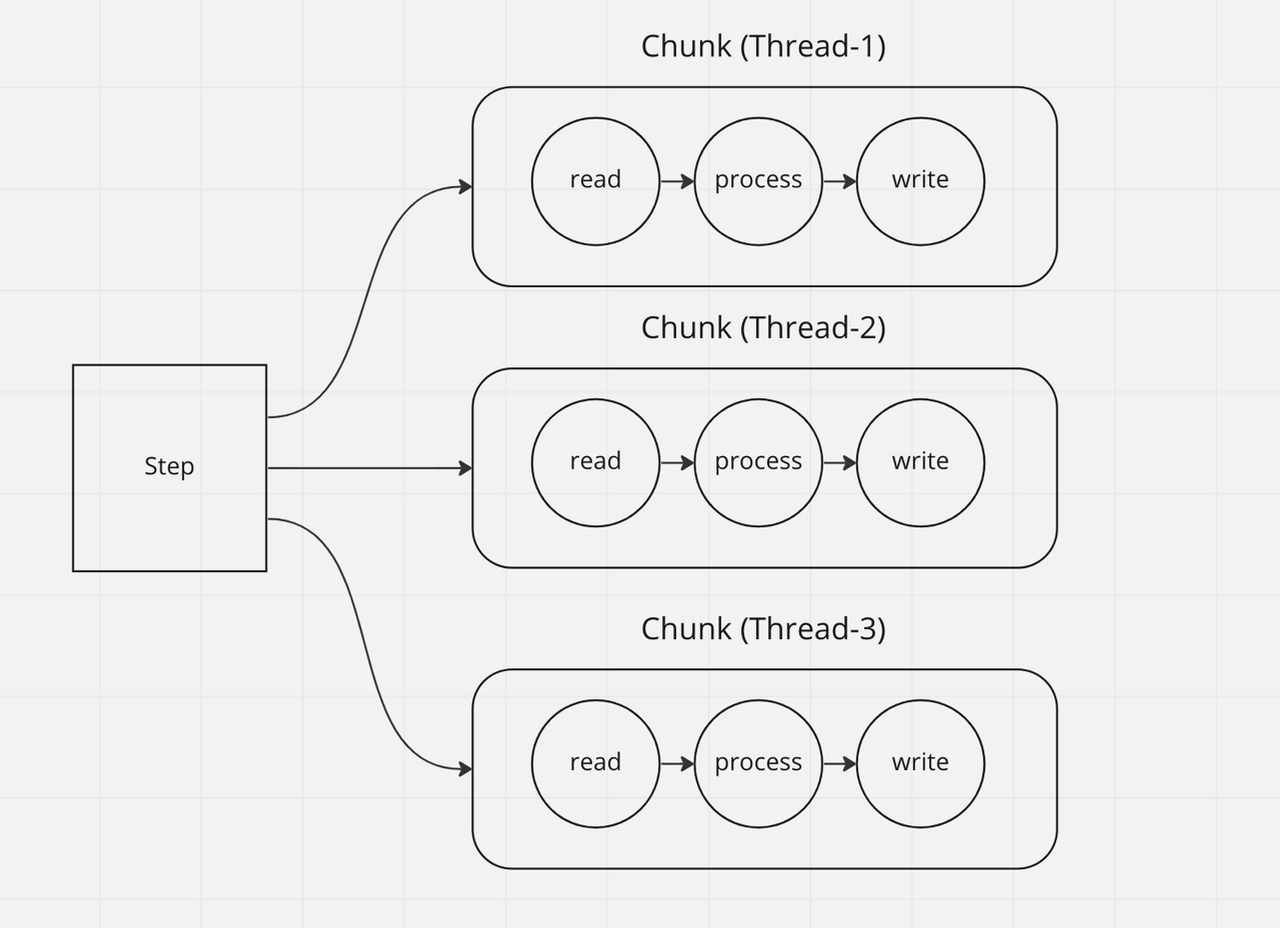
Multi-threaded Step의 핵심은 하나의 스레드에서 chunk를 처리합니다.
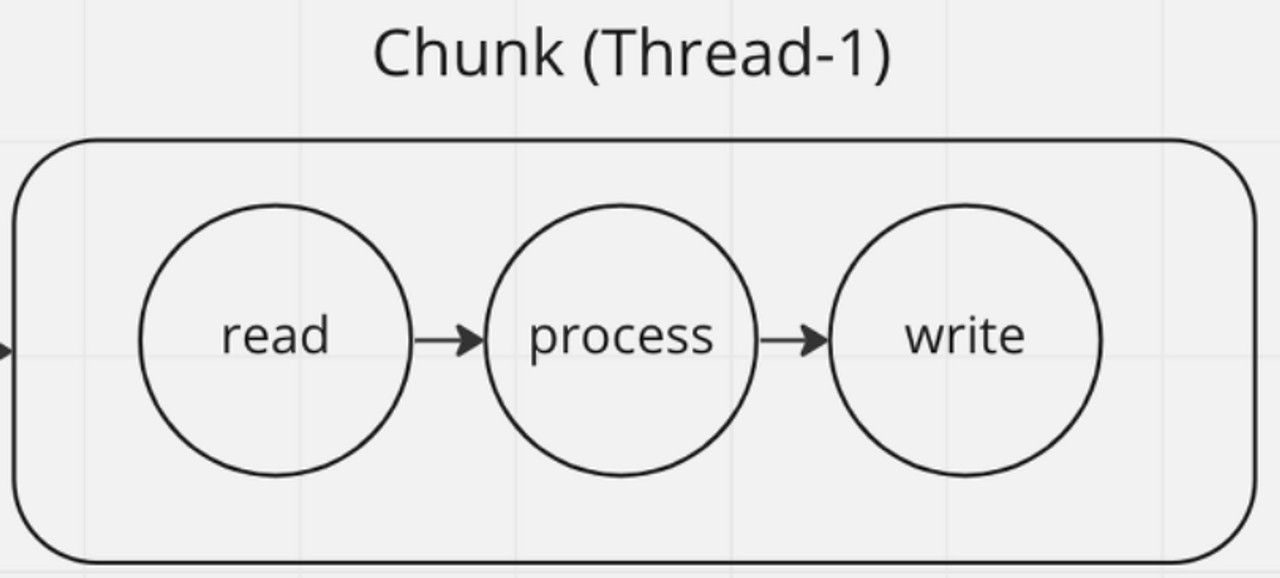
하나의 스레드에서 데이터를 읽고, 가공하고, 쓰는 과정을 처리합니다.
이러한 스레드를 여러개 만들어 chunk를 동시에 처리합니다.
Multi-threaded Step은 read, process, write 모든 부분에서 병렬 처리가 적용됩니다.
Multi-threaded Step방식은 Chunk처리 단위 자체를 병렬 처리하기 때문에 Reader, Processor, Writer 모든 부분이 병렬 처리됩니다. 따라서 어떤 부분에 병목이 발생하던지 처리 속도 개선에 효과적입니다.
그러나 병렬 처리가 많은 부분에서 적용된다는 점은 그만큼 동시성 문제를 고려할 부분이 늘어나는 것을 의미합니다.
Multi-threaded Step 적용이 가장 간단합니다.
Spring Batch에서 지원하는 병렬 처리 기능은 배치 로직을 수정하지 않고도 간단히 적용할 수 있는 게 장점입니다. Multi-threaded Step는 특히 적용이 간단합니다.
fun step(): Step {
return stepBuilderFactory["step"]
.chunk<Int, Int>(5)
.reader(itemReader())
.processor(itemProcessor())
.writer(itemWriter())
.taskExecutor(taskExecutor())// taskExecutor 지정
.throttleLimit(3)// 스레드 수 지정
.build()
}
taskExecutor, throttleLimit 정도만 지정해 줘도 간단히 사용할 수 있습니다.
Multi-threaded Step은 트랜잭션 처리가 용이합니다.
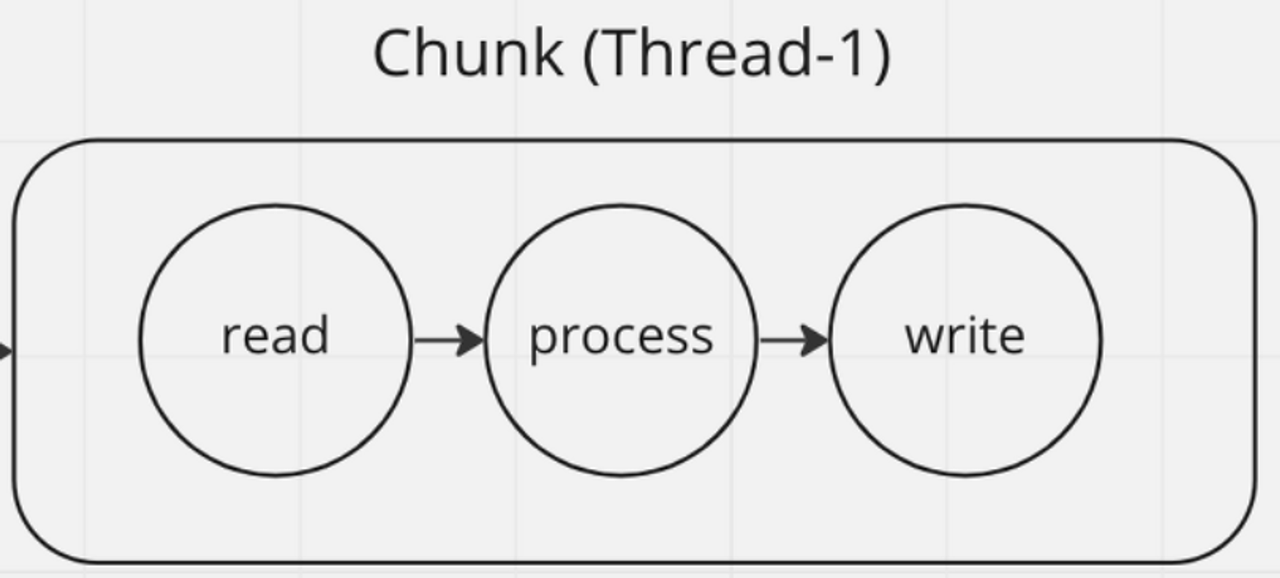
read, process, write과정이 하나의 스레드에서 처리됩니다.
병렬 처리에서 트랜잭션 관리가 어려운 점은 파생되는 스레드는 트랜잭션 처리할 수 없다는 부분입니다.
Multi-threaded Step은 chunk처리 과정에서 새로운 스레드가 파생되지 않습니다.
스레드 내부에서 트랜잭션이 열리고 데이터를 읽고, 가공하고, 쓰는 작업을 통해 트랜잭션 처리가 용이합니다.
Multi-threaded Step은 Chunk 단위 처리 순서를 보장할 수 없습니다.
Multi-threaded Step를 적용하면 Thread-1, Thread-2, Thread-3중 어떤 chunk가 먼저 처리될까요?
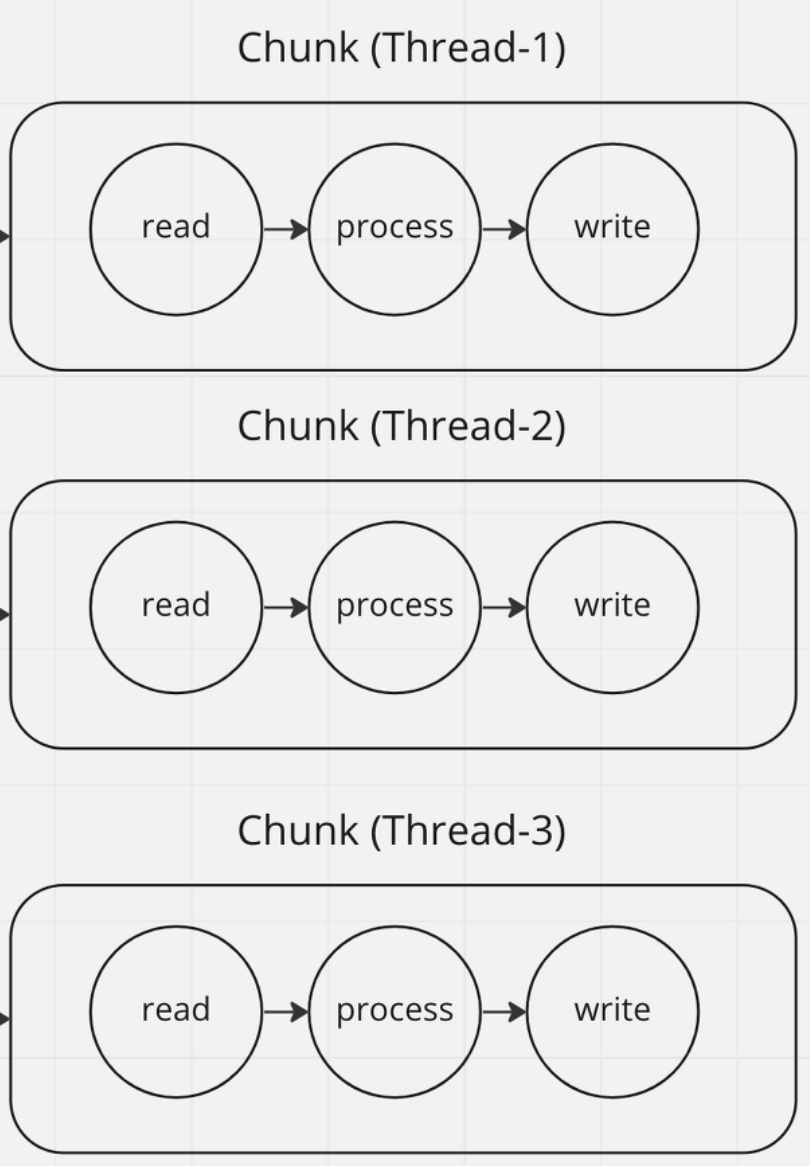
알 수 없습니다. 어떤 스레드의 chunk처리가 먼저 끝나는지 보장할 수 없습니다.
chunk 처리 순서를 보장할 수 없다면 비즈니스 로직상 순서 처리가 중요한 배치에는 적용할 수 없습니다.
또한, itemStream으로 정확한 배치 처리 상태를 기록할 수 없게됩니다. ItemStream은 chunk처리 과정 중 일부로 처리되므로 ItemStream의 update에 동시성 문제가 발생합니다. 결과적으로 배치 재시작 시 데이터 중복 처리나 데이터를 누락하는 상황이 발생할 수 있습니다.
Multi-threaded Step은 DB connection pool size에 대한 고려가 필요합니다.
Spring Batch에서는 Chunk단위로 트랜잭션이 발생합니다. Multi-threaded Step은 스레드마다 chunk가 할당되어 처리되기 때문에 스레드 수와 비례하여 트랜잭션이 발생합니다. 그러므로 chunk 처리 속도, connection pool size, 실행 스레드 수의 균형을 적절히 맞추지 못한다면 다음과 같은 에러 메시지를 만나기 쉽습니다.
Connection is not available, request timed out after..AsyncItemProcessor
AsyncItemProcessor는 process로직을 병렬 처리하는 방식입니다. 아래 이미지를 참고해 주시면 되겠습니다.
(AsyncItemProcessor를 사용하기 위해서는 spring-batch-integration 의존성이 별도로 필요합니다)

AsyncItemProcessor는 Chunk 내부 처리 로직 중 process에서 새로운 스레드를 만들어 처리합니다.
process의 처리 결과로 Future를 반환하고 Writer에서 Future의 결과를 종합하여 처리합니다.
기존 Processor, Writer는 AsyncItemProcessor, AsyncItemWriter에 위임하여 코드 수정 없이 이러한 동작을 수행할 수 있습니다.
여기서 주의할 점은 AsyncItemWriter라고 writer로직이 병렬 처리되는 것은 아닙니다.
AsyncItemWriter는 단순히 Future를 취합하여 writer에 전달될 데이터를 모은 뒤 위임된 write메서드를 호출하는 역할을 합니다.
AsyncItemProcessor은 비교적 구현이 간단합니다.
앞서 소개한 Multi-threaded Step보다는 코드가 복잡하지만 그렇게 어렵지는 않습니다.
fun step(): Step {
return stepBuilderFactory["step"]
.chunk<Int, Future<Int>>(5)// write는 future로 받음
.reader(itemReader())
.processor(asyncItemProcessor())
.writer(asyncItemWriter())
.build()
}
fun asyncItemProcessor(): AsyncItemProcessor<Int, Int> {
val asyncItemProcessor = AsyncItemProcessor<Int, Int>()
asyncItemProcessor.setDelegate(itemProcessor())// processor 위임
asyncItemProcessor.setTaskExecutor(taskExecutor())
return asyncItemProcessor
}
fun asyncItemWriter(): AsyncItemWriter<Int> {
val asyncItemWriter: AsyncItemWriter<Int> = AsyncItemWriter()
asyncItemWriter.setDelegate(itemWriter())// writer 위임
return asyncItemWriter
}
병렬 처리의 스레드 수는 chunk size에 영향을 받습니다.
chunk size와 별개로 처리 스레드에 제한을 두고 싶다면 taskExecutor를 ThreadPool size를 설정하여 제어할 수 있습니다.
AsyncItemProcessor은 process만 병렬 처리합니다.
AsyncItemProcessor는 process만 병렬 처리되기 때문에 Multi-threaded Step과 비교하면 동시성 문제에 비교적 덜 복잡한 편입니다. 그런 이유로 병목이 reader, writer에서 발생한다면 처리량이 증가하는 효과를 크게 볼 수 없습니다.
AsyncItemProcessor은 Chunk단위의 처리 순서 보장합니다.
Multi-threaded Step방식과는 다르게 chunk단위는 순차 처리되며 chunk 내부의 process가 병렬 처리됩니다. chunk단위의 처리 순서가 보장이 되기 때문에 itemStream적용에도 문제 없습니다
AsyncItemProcessor은 트랜잭션 관리가 어렵습니다.
가장 처음에 언급드렸던 트랜잭션 범위와 관련된 문제가 AsyncItemProcessor에서는 동일하게 적용됩니다.
process에서 별도의 스레드를 파생시키므로 새로운 스레드는 Chunk 트랜잭션 범위 밖으로 처리되어 주의가 필요합니다.
AsyncItemProcessor은 Process예외가 Writer에서 처리됩니다.
Future가 ItemWriter에서 unWrapping 되기 때문에 process의 예외가 Writer에서 처리됩니다.
만약 ItemProcessListener를 구현하셨다면 onProcessError가 호출되지 않습니다.
이런 동작 방식이 영향을 줄 수 있는 대표적인 기능이 배치의 skip입니다. skip은 process, write 어디서 발생하는지에 따라 동작 방식이 달라지기 때문입니다. 따라서 의도치 않게 동작 방식이 변경되는 부분도 인지하고 있어야합니다.
Partitioning
partitioning은 step을 특정 조건으로 파티셔닝하고 파티셔닝 된 step을 병렬 처리하는 방식입니다.
(여기서 편의상 파티션을 매니징 하는 step을 manager, 파티션 되어 데이터를 처리하는 step을 worker라고 표현하겠습니다)
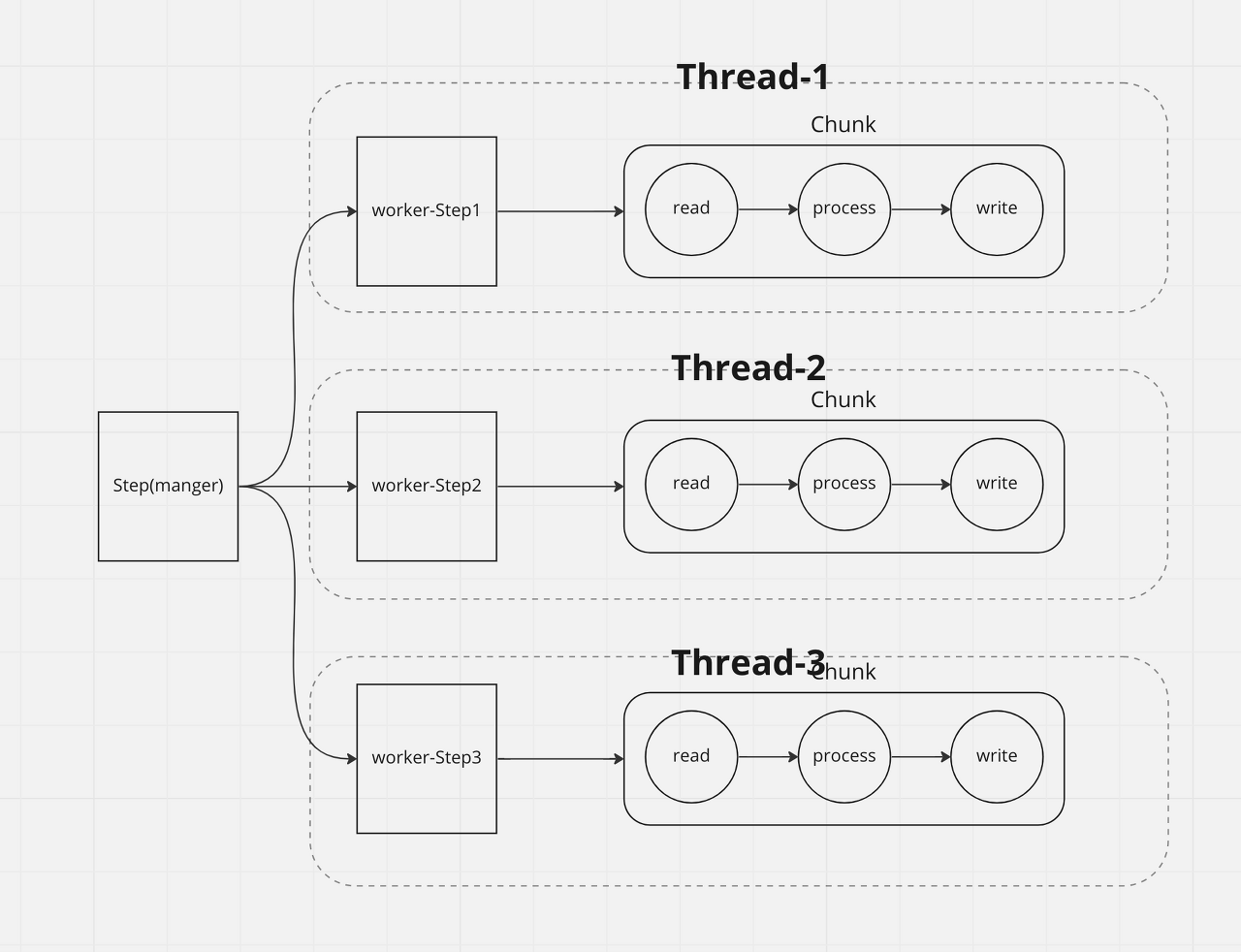
언뜻 보면 Multi-threaded Step 처리 방식과 유사하다고 생각하실 수도 있을 것 같습니다.
Multi-threaded Step은 Thread에 Chunk를 할당하여 처리하는 방식입니다.
Partitioning은 Thread에 Step을 할당하여 처리하는 방식입니다. (더 큰 Step개념에서 데이터를 처리합니다)

Step은 StepExecution, StepExecutionContext를 갖기 때문에 worker Step마다 개별적인 실행 상태를 관리할 수 있습니다.
Partitioning은 트랜잭션 관리가 용이합니다.
chunk 내부 로직은 동일한 스레드에서 처리됩니다. chunk 처리 과정 중 새로운 스레드가 파생되지 않으므로 트랜잭션 관리가 용이합니다.
Partitioning은 일부 Worker Step 실패 시 다른 Worker step에 영향을 주지 않습니다.
다른 병렬 처리 방식은 예외를 만나면 기본적으로 배치 애플리케이션이 종료됩니다.
그러나 partitioning은 일부 worker step에서 예외가 발생하여 종료되더라도 다른 worker step에는 영향을 주지 않습니다. 모든 worker step들이 종료되고 그 결과를 manager step에서는 집계하여 배치의 최종 성공, 실패 상태를 기록합니다.
이런 동작 과정은 일부 실패한 데이터를 제외하고 나머지 데이터를 처리하고 싶을 때, 재처리를 위해 실패에 대한 데이터의 context를 관리하고 싶을 때 유용합니다.
예를 들어 배치 애플리케이션으로 A, B , C,.... Z의 종류의 데이터를 처리해야 한다고 가정해 보겠습니다.
A read -> A process -> A write
B read -> B process -> B write
C read -> C process -> C write
...
Z read -> Z process -> Z write
A의 데이터를 처리하던 중 예외가 발생하면 배치 애플리케이션이 종료되고 나머지 데이터는 처리되지 못합니다.
A read -> A process -> A write// 예외 발생
B read -> B process -> B write// 처리되지 못함
C read -> C process -> C write// 처리되지 못함
...
Z read -> Z process -> Z write// 처리되지 못함
여기서 예외가 발생한 A 데이터를 제외하고 나머지를 처리한다면 배치 실패에 대한 영향도를 최소화할 수 있습니다.
Spring Batch의 Skip을 사용해도 되지 않나요?
실패한 데이터를 다시 처리해야 한다면 Skip을 사용해서는 안됩니다. Skip이 발생해도 최종적으로 배치는 성공 처리되며 실패에 대한 기록이 없어 배치를 재처리한다고 해도 어떤 데이터를 처리해야 하는지 파악하기 어렵습니다.
여기서 데이터 종류별 파티셔닝을 적용해 볼까요?
A read -> A process -> A write// 예외 발생 worker-1
B read -> B process -> B write// 처리 완료 worker-7
C read -> C process -> C write// 처리 완료 worker-4
...
Z read -> Z process -> Z write// 처리 완료 worker-10
실패되는 A데이터를 제외하고는 모두 처리 완료됩니다. 하지만 A데이터 처리에 실패했기 때문에 최종적인 집계결과로 배치는 실패 상태로 기록됩니다. 이 배치를 재시작한다면 이미 성공한 Step을 제외하고 실패한 Step(A데이터 처리 Step)만 재실행됩니다.
경우에 따라서는 배치 애플리케이션에 따라서 일부 성공 상태가 의미 없을 수도 있습니다. 모든 데이터 처리가 성공해야만 한다면 나머지 데이터 처리하지않고 배치 실패를 빠르게 발생시켜 인지하는 편이 나을 수도 있기 때문에 partitioning의 동작이 적절한지 판단이 필요합니다.
Partitioning은 구현이 복잡합니다.
파티셔닝 Step을 구현하기 위해서는 어떤 기준으로 데이터를 파티셔닝 해야 하는지를 결정하고 이를 코드상으로 구현해야 합니다. 다른 병렬 처리 방식에 비해 구현해야 하는 코드가 많고 복잡하기 때문에 사실 자주 사용되는 방식은 아닙니다.
Partitioning은 Chunk 단위 처리 순서를 보장할 수 없습니다.
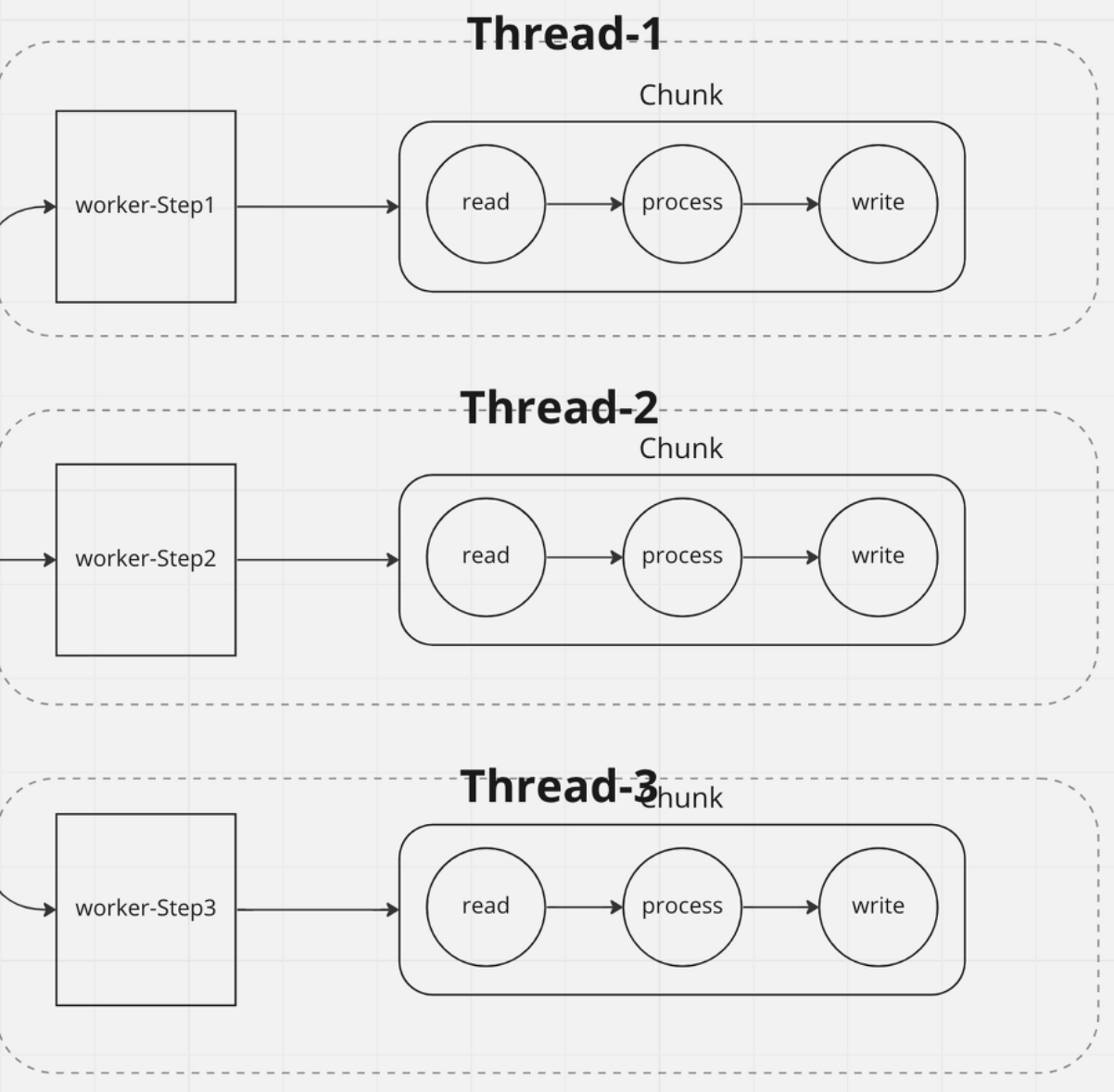
Multi-threaded Step과 유사하게 스레드마다 chunk를 처리하므로 데이터 처리 순서를 보장할 수 없습니다.
반면 Multi-threaded Step과는 다르게 ItemStream적용에는 문제가 없습니다. Worker Step은 각자의 StepExecution, StepExecutionContext를 가지기 때문에 Step의 처리 상태가 개별적으로 관리되고 업데이트됩니다.
마치며
Spring Batch에서 사용할 수 있는 대표적인 병렬 처리 방식 각각의 특징을 정리해봤습니다.
본문의 내용을 요약을 하자면 아래와 같습니다.
Multi-threaded Step
- read, process, write 모든 부분에서 chunk단위로 병렬 처리되므로 성능 개선에 효과적
- 동일한 스레드에서 chunk가 처리되므로 트랜잭션 관리에 용이함
- chunk단위로 병렬 처리되므로 chunk처리 순서를 보장해주지 않음 (비즈니스 처리 순서, ItemStream제약)
- 동시성 문제를 고려해야하는 부분이 많음
- 적용이 가장 간단함
AsyncItemProcessor
- process로직만 병렬 처리하므로 병목 지점이 process일 경우 효과적
- chunk처리 순서가 보장되므로 처리 순서가 중요한 배치, itemStream사용에 제약 없음
- process처리에 새로운 스레드가 파생되므로 트랜잭션 관리가 어려움
- process로직만 동시성 문제를 고려해주면 되므로 비교적 간단함
Partitioning
- Step을 특정 기준으로 나눠 Sub Step을 만들고 각각 데이터를 처리함
- step단위로 병렬 처리되므로 chunk처리 순서가 보장되지 않음
- 파티션된 step은 StepExecution을 개별적으로 가지므로 ItemStream사용에 제약이 없음
- 일부 Step이 실패해도 나머지 Step은 정상처리되고 마지막 집계 결과 실패를 반환함
- 구현이 가장 복잡함
작성하는 배치 애플리케이션의 병목 지점은 어디인지, 트랜잭션으로 관리되어야하는지, 처리 순서를 보장해야하는지등 다양한 조건에 따라 적절한 병렬 처리 방식이 달라질 수 있습니다.
'Spring Batch' 카테고리의 다른 글
| Spring Batch 실패를 다루는 기술 - ItemStream (0) | 2023.01.07 |
|---|
